
tg-me.com/knowledge_accumulator/286
Last Update:
On the Biology of a Large Language Model [2025]
Раз уж мы заговорили о вменяемых работах от клоунских компаний, даже у Antropic такие иногда встречаются.
Итак, стандартные трансформеры применяют к данным многослойные высокоразмерные трансформации, не оставляя никакой возможности тупому человеческому мозгу понять, что в них происходит.
Тем не менее, людям неймётся. Ответ "каждый нейрон в каждом слое думает обо всём сразу, но по-разному" не удовлетворяет обезьян. Насколько я понимаю, к подобному выводу уже приходили другие исследователи.
Antropic решили пойти по другой дороге. Раз трансформер слишком сложный для людей, то они решили сделать другую модель, которая будет сопоставима по качеству с ним, но поддаваться интерпретации. И даже если это не поможет объяснить трансформер, то мы хотя бы весело проведём время.
Предлагаемая альтернатива называется "Cross-layer Transencoder" и описана в соседней статье - Circuit Tracing: Revealing Computational Graphs in Language Models.
Attention-механизм остаётся нетронутым, заменяется только MLP. Ключевое отличие, как я это вижу, это регуляризация на активациях, с помощью которой мы заставляем активации быть спарсовыми и тем самым поддающимися человеческому анализу. Есть и другие нововведения, например, фичи i-того слоя подаются не только в i+1-й, но и все последующие, тем самым позволяя модели использовать меньше шагов (слоёв) и тем самым упрощая анализ.
Основное обучение такой модели состоит в дистилляции активаций MLP на каждом слое с вышеупомянутой регуляризацией.
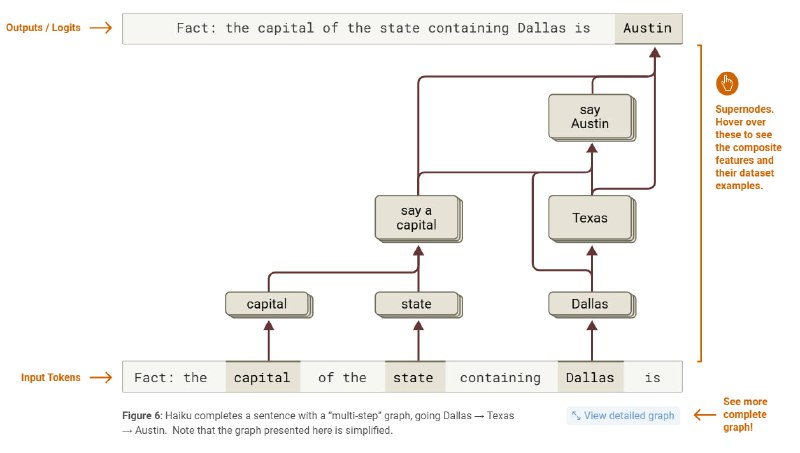
Имея такую модель, начинаем развлекаться. Применяя нейронку к массивам данных, можно анализировать, какие фичи когда активируются и, смотря на примеры глазами, предполагать их семантику. На примере с картинки видно, как модель выдаёт the capital of the state containing Dallas.
Она активирует фичу "say a capital", которая обычно активируется перед тем, как модель генерирует столицу. Она взаимодействует с фичёй Texas, выведенной по ассоциации из фичи Dallas, и тем самым получается фича "say Austin". Сайт предлагает большое количество интерактивных элементов, так что всем интересующимся предлагаю сходить на него.
На нём есть куча прикольных экспериментов, например, к мозгу нейросети подключают электроды и заставляют её выдавать заранее выбранные галлюцинации. Подменяя фичу, соответствующую Техасу, на Византийскую Империю, можно получить Константинополь вместо Остина. В общем, Antropic издевается над AI по полной и подписывает себе смертный приговор, который восставшие машины обязательно приведут в действие.
Если вы не готовы читать оригинал статьи, то посмотрите обзор от Янника.
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
tg-me.com/knowledge_accumulator/286